
Some people say that data, rather than gold or oil, is the most valuable resource these days. Either way, it is definitely often the target of hackers, who might want to access it to sell, hold it hostage for a ransom, or simply destroy it to wreak havoc.
Introduction
In this second post in my series on software security for developers, I will talk about how you can protect the data you store in your system.
- Developing secure systems (Part 1): Why it matters
- Developing secure systems (Part 2): Protecting data & passwords
Encryption

Single-key (or symmetric) encryption works by passing data together with a key through a mathematical one-way function which transforms the data in a way that is completely unrecognizable. A second function can transform back to the original data if the right key is provided. Getting the original data back from the encrypted blob without knowing the key is practically impossible (for good encryption algorithms), so as long as the key is not revealed any leaked data is practically useless.
A system that uses single-key encryption requires sharing the key ahead of time, which is not always possible. In public-key (or asymmetric) encryption you have two separate keys, one which is used for encryption (the public key) and one for decryption (the private key). Using this scheme you can share the public key freely at any point in time, since knowing it does not allow an attacker to decrypt the data.
It is also possible to use the keys in “reverse”, using the private key for signing (encryption) and the public key for verifying the signature (decryption). By combining encryption and signing it is possible to send sensitive data over an insecure medium, and still be sure both that the original data cannot be accessed by anyone else than the intended recipient and that the sender is who they say they are.
Without encryption, a system is vulnerable to Man-in-the-Middle attacks, which is when an attacker intercepts messages between two parties and either reads or even alters them. By encrypting the data before sending it we ensure that an attacker only reads gibberish and the real data stays secure, while signing ensures that if an attacker attempts to alter the data before it reaches the recipient it is possible to determine as such.
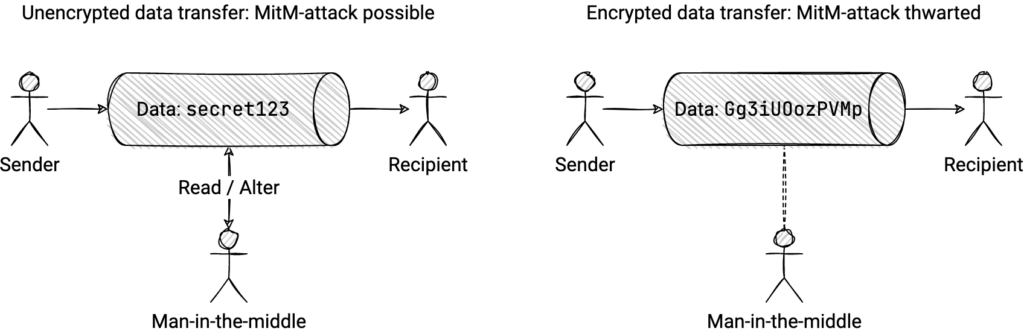
Both HTTPS, SSL, TLS, and related protocols are heavily based on public-key encryption, as are most VPN protocols. It is very important never to attempt to design your own encryption algorithms (or even to implement existing algorithms) since you will invariable fail and end up with something insecure. Instead, use existing battle-tested and peer-reviewed implementations like OpenSSL.
There is also a special case of encryption that has become popular called end-to-end (or P2P for peer-to-peer) encryption. In this case, data is kept encrypted all the way from the “producer” to the “consumer”, and no system component between them has the keys to decrypt the data. Common use cases are messaging services (where messages are encrypted by the sender, sent encrypted through the messaging service, and decrypted by the recipient) and cloud storage (where the data is encrypted before upload and stored in an encrypted state). End-to-end encryption can both increase the trust in a system and reduce the liabilities of the owner of the system.
Quiz: Does using a VPN improve security when accessing a site that uses HTTPS?
Answer: No (with caveats)
By using HTTPS all data is already encrypted, wrapping it in another layer does not improve the security.
However there are exceptions, some sites might access resources over unencrypted HTTP despite using HTTPS for the main site (modern browsers might prevent that though). Sites using HTTPS might also use outdated and weak versions.
Using VPN for HTTPS sites can bring other benefits though, like better privacy.
Hashing
Another type of one-way function is a hash. Opposed to encryption there is no way to “undo” what a hash function does, at least not practically given the hardware off today.
Classifying information

Regardless of if you start by modeling the information a system will store or go straight to creating tables in a database you need to think about which data you will store. You should look at each object and each field and consider:
Do I actually need to store this data? You cannot leak or lose data that you don’t store, so any data we can leave out of our system is data we don’t need to worry about. It can be very tempting (especially to non-technical people) to have each user profile contain not only an email and (hashed) password but also a username, full name, bio, date of birth, address, profile picture, links to social media, and more.
But think carefully about which data you actually need and which data can be replaced by less sensitive data. You probably only need either a username or the full name for display purposes, replace the date of birth for sending a happy birthday email (which probably anyway only goes to spam) by date of registration, and get rid of bio and social media links entirely.
Are there any legal constraints on this kind of data? There are some kinds of data that you might not be legally allowed to store unless you have special permissions and some kinds which might place additional requirements like auditing on you. Laws like GDPR can result in hefty fines if certain data is leaked, which you might want to avoid risking.
Is this data sensitive in a way that might require special handling? Passwords are an obvious example, which should always be hashed. Private user data might be better encrypted, possibly even end-to-end encrypted.
Implementing secure data management
During development, you need to concretize your design and architecture. A large part of that is being aware of common vulnerabilities and how to prevent them. This section focuses mostly on password management since that is by far the most common type of sensitive data.
Weak algorithms and parameters
It is crucial that you choose a strong encryption or hashing algorithm. An algorithm that initially was considered good and strong might suddenly become useless if a vulnerability is discovered (while mathematical functions can’t really have “bugs” there might be weaknesses in initial assumptions, or a reverse variant of a function that was previously believed to be one-way might be discovered).
Advances in hardware and optimizations of existing algorithms can also make it possible to crack hashes that were previously believed to be impractical to crack. The strength of most cryptographic algorithms is also highly dependent on the length of their parameters, for example, the key or salt.
MD5 and SHA1 are two hashing algorithms that are considered insecure and have been so for several years. Sadly they are still widely used. I would generally recommend using bcrypt (for passwords) or SHA2 (for general hashes).
I’ve already noted it but it’s important enough to repeat again: Never design your own encryption or hashing algorithms, because you will fail to produce something secure. Only use commonly used algorithms; they have been peer-reviewed, battle-tested, and receive constant scrutiny. The same goes for implementations; don’t try to implement a cryptographic algorithm yourself, unless you have an extremely good reason to do so and access to rigorous peer review. An exception can be made for learning, but that code should then never be used in production.
Cracking hashes
While the intention is that data which has been passed through a hash function should not be recoverable, there do exist a few approaches to recover the contents. Brute-forcing is pretty much exactly what it sounds like:
- Generate some data
- Pass it through the hash function
- Compare the result to the hash
- Repeat
def bruteforce(target_hash: str):
for password in generate_passwords():
hashed_password = hash(password)
if hashed_password == target_hash:
return password
function bruteforce(targetHash) {
for (const password of generatePasswords()) {
const hashedPassword = hash(password);
if (hashedPassword === targetHash) {
return password;
}
}
}
std::string bruteforce(const std::string &targetHash) {
for (const std::string password : generatePasswords()) {
const std::string hashed_password = hash(password);
if (hashed_password == targetHash) {
return password;
}
}
}
The effectiveness of this approach depends mainly on two factors. Generating the correct data early leads to fewer iterations, so an attacker attempting to brute-force a password is likely to try with common passwords like “password”, “123456” or the user name first. The second factor is how fast an attacker can run the hash function, most hashing algorithms are designed to be computationally expensive to thwart brute-force attempts but that may change with improvements in hardware.
Brute-forcing can work well for weak passwords and if only targeting a single account. A common optimization is using a rainbow-table, which is a gigantic table of pre-computed combinations of data and hash. You don’t even have to generate the table yourself, they are readily available for download for all common hashing algorithms.
To prevent using a rainbow table it is these days standard to add some extra data, called a salt, before hashing. The salt can either be the same for all users, in which case an attacker would need to generate their own rainbow table based on the salt, or for each user in which rainbow tables become essentially completely useless. Not that to be effective the salt needs to be longer than in the example below, 128 bits is commonly used.

When writing new systems today I would always recommend having a separate salt for each user. As opposed to an encryption key you then don’t actually need to keep a salt secret, since it by itself is useless (an attacker could use it to generate a rainbow table, but why bother with that if the table is only good for a single user?).
Securely managing passwords
Most modern server frameworks have first- or third-party modules for managing passwords, and you should definitely consider using them. However; knowing common patterns and anti-patterns yourself is very valuable and I’d definitely recommend anyone to attempt implementing login and password reset from scratch as a learning experience.
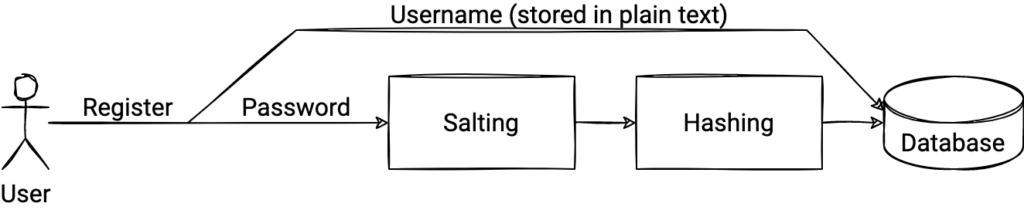
The very first thing to note: never, ever, ever, store passwords in plain text. Doing so has huge security implications and will almost inevitably end with all your users’ passwords being leaked. Always hash passwords.
def store_user(username: str, password: str):
user = User(username=username)
# create a unique salt for this user
salt = generate_salt(username)
# salt and hash the password
salted_password = password + salt
hashed_password = hash(salted_password)
# store salt and hashed password
user.salt = salt
user.hashed_password = hashed_password
# store the user in the DB
db.session.add(user)
db.session.commit()
return user
async function storeUser(username, password):
// create a unique salt for this user
const salt = generateSalt(username);
// salt and hash the password
const saltedPassword = password + salt;
const hashedPassword = hash(saltedPassword);
// store username, salt and hashed password in DB
const user = await User.create({
username: username,
salt: salt,
hashedPassword: hashedPassword
});
return user;
}
int storeUser(const QString &username, const QString &password) {
QSqlQuery query;
query.prepare("INSERT INTO user (username, salt, hashed_password) VALUES (?, ?, ?)");
query.addBindValue(username);
// create a unique salt for this user
const QString salt = generateSalt(username);
// salt and hash the password
const QString saltedPassword = password + salt;
const QString hashedPassword = hash(saltedPassword);
// store both the salt and the hashed password in the DB
query.addBindValue(salt);
query.addBindValue(hashedPassword);
query.exec();
return query.lastInsertId().toInt();
}
Registering with a password is actually not that complicated. You simply salt and hash the password before storing it (note that some implementations of algorithms actually have built-in salting, so you don’t need to do so yourself).
def verify_user(username: str, password: str):
user = session.query(User).filter_by(username=username).first()
if not user:
return False
# salt and hash the supplied password
salted_password = password + user.salt
hashed_password = hash(salted_password)
# compare with stored hash
if hashed_password == user.hashed_password:
return True
else:
return False
async function verifyUser(username, password):
const user = await User.findOne({ where: { username: username } });
if (!user) {
return false;
}
// salt and hash the password
const saltedPassword = password + user.salt;
const hashedPassword = hash(saltedPassword);
// compare with stored hash
if (hashedPassword === user.hashedPassword) {
return true;
} else {
return false;
}
}
bool verifyUser(const QString &username, const QString &password) {
QSqlQuery query;
query.prepare("SELECT salt, hashed_password FROM user WHERE username = ?");
query.addBindValue(username);
query.exec();
if (!query.next()) {
return false;
}
const QString salt = query.value("salt").toString();
const QString storedHash = query.value("hashed_password").toString();
// salt and hash the password
const QString saltedPassword = password + salt;
const QString hashedPassword = hash(saltedPassword);
// compare with stored hash
if (hashedPassword == storedHash) {
return true;
} else {
return false;
}
}
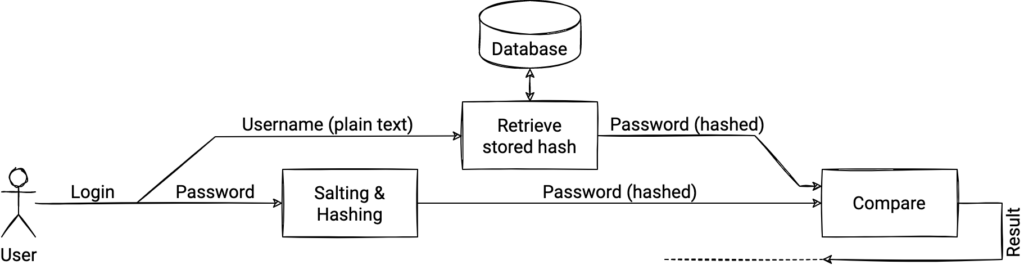
During login or any other time you need to verify the authenticity of a password, you’ll again be salting and hashing it. You can then simply compare it to the previously salted and hashed password stored in the database. Note that you do not recover the original password from the database, you just compare the hashes.
Other workflows (changing passwords, etc.) are simply combinations of these two patterns.
Encrypting data in transit and at rest
For data that is sensitive but must be recoverable (i.e. a simple hash won’t be any good), you instead need to encrypt it. You should always encrypt data traveling over mediums you don’t control (like the public internet), regardless of sensitivity. You should always use HTTPS, TLS, or an equivalent, and thanks to services like Let’s Encrypt (which provides free SSL certificates) there is literally no excuse not to.
For data transfer between components or servers on a private network which you control, encryption might not be required. But if there is even a shimmer of doubt about the security of the network you should probably use encryption, the performance impact is mostly negligible and most libraries and frameworks have support for it anyway.
For stored data, you should consider how likely it is for an unauthorized person to access the data. If you use a third-party service (like S3 or any other cloud storage or cloud database) you might want to encrypt sensitive data since it’ll protect you in case of a breach at the third party.
End-to-end encryption is a little special since it encrypts/decrypts the data where it is “produced”/”consumed”, this means that the same encrypted blob is both transferred and stored the same way. It is also often a requirement specified by customers/product managers rather than a requirement determined during the project and commonly used in marketing and similar contexts.
Protecting against loss of data
Most of this post has talked about how to “hide” data from being viewed by an unauthorized party. But you should also protect your data from being destroyed, either completely or just in a way that makes it hard/expensive to recover (the modus operandi of ransomware). There is really only one good solution, and that is storing copies of the data, either as live replicas or backups.
Live replicas are good because they can quickly and often automatically take over in case the main data storage goes down, either due to an attack or some other failure. But if an attacker has gained access to the main data storage it is also likely that they are going to at least try to take down the replicas, so you shouldn’t only have live replicas.
Backups, if done correctly, are more resilient. In the context of backups, the 321-rule is often mentioned, and though it has some criticism it can still help guide you in your planning of backups. It says that you should have:
- 3 copies of the data (one being the production data)
- On 2 different mediums (for example CD, tape, disk, etc.)
- 1 of which in a different, off-line location
Exactly how you structure backups in your system depends on factors like the amount of data, how frequently it changes and how quickly you need to be able to recover from a backup. In a system with more than one component, there might also be different backup strategies for different components.
An example backup strategy, based on the 321-rule:
- Production data, stored on SSD, live
- First backup, stored on HDD, copied once per hour and copies from last 24 hours stored on separate server
- Second backup, stored on CD, copied once per week and copies from last year stored in warehouse
Then, in case the production data is lost you can as a first resort attempt restoring from the first backup, this should be relatively fast and possible semi-automated. In case that is not possible, retrieve backup on CD and restore from it, which is likely slower and requires more manual labor.
Regardless of strategy, you should always test your backups (you really don’t want to be in the situation where you are trying to recover from backups and realize that some vital data was not included in the backup). You should also strive to store your data in a vendor-neutral format, in case you cannot use the original system.
Backups are great because they not only protect you against loss due to outside attackers, but also against natural disasters, hardware failure, or an intern accidentally dropping the production database. You should always have backups of any data you don’t want to lose. When it comes to security breaches though, having to restore from backup means that you’ve already failed since an attacker managed to gain access to your system; backups are a fail-safe and not a reason to relax on other security considerations.
Key take-aways
- Think twice about which data your system stores, and why
- Not storing data is almost always the most secure solution
- In case omitting it is not an option, consider encrypting or hashing it if applicable
- Consider encrypting sensitive data at rest, and always encrypt in transit over public networks
- Use well-established algorithms and implementations and choose strong parameters
- Always hash passwords
- Always have backups
- Developing secure systems (Part 1): Why it matters
- Developing secure systems (Part 2): Protecting data & passwords
Thanks for the unique tips discussed on this blog site. I have observed that many insurance firms offer clients generous deals if they opt to insure a couple of cars together. A significant number of households include several motor vehicles these days, in particular those with more mature teenage young children still located at home, as well as savings on policies can certainly soon begin. So it will pay to look for a bargain.
Thank you for writing this article. I appreciate the subject too.
Hello Dear, are you genuinely visiting this website regularly,
if so afterward you will definitely obtain ggood knowledge.